Currently working at TipTip to build a one-stop platform for content-creators.
Previously at Kodefox, Phantom Network, and GDIS.
Here are some of my work in the past. You can view all my work here.
Develop
TipTip
TipTip is an all-rounded entertainment platform with a comprehensive array of features that facilitate events and gathering activities.
Build at TipTip
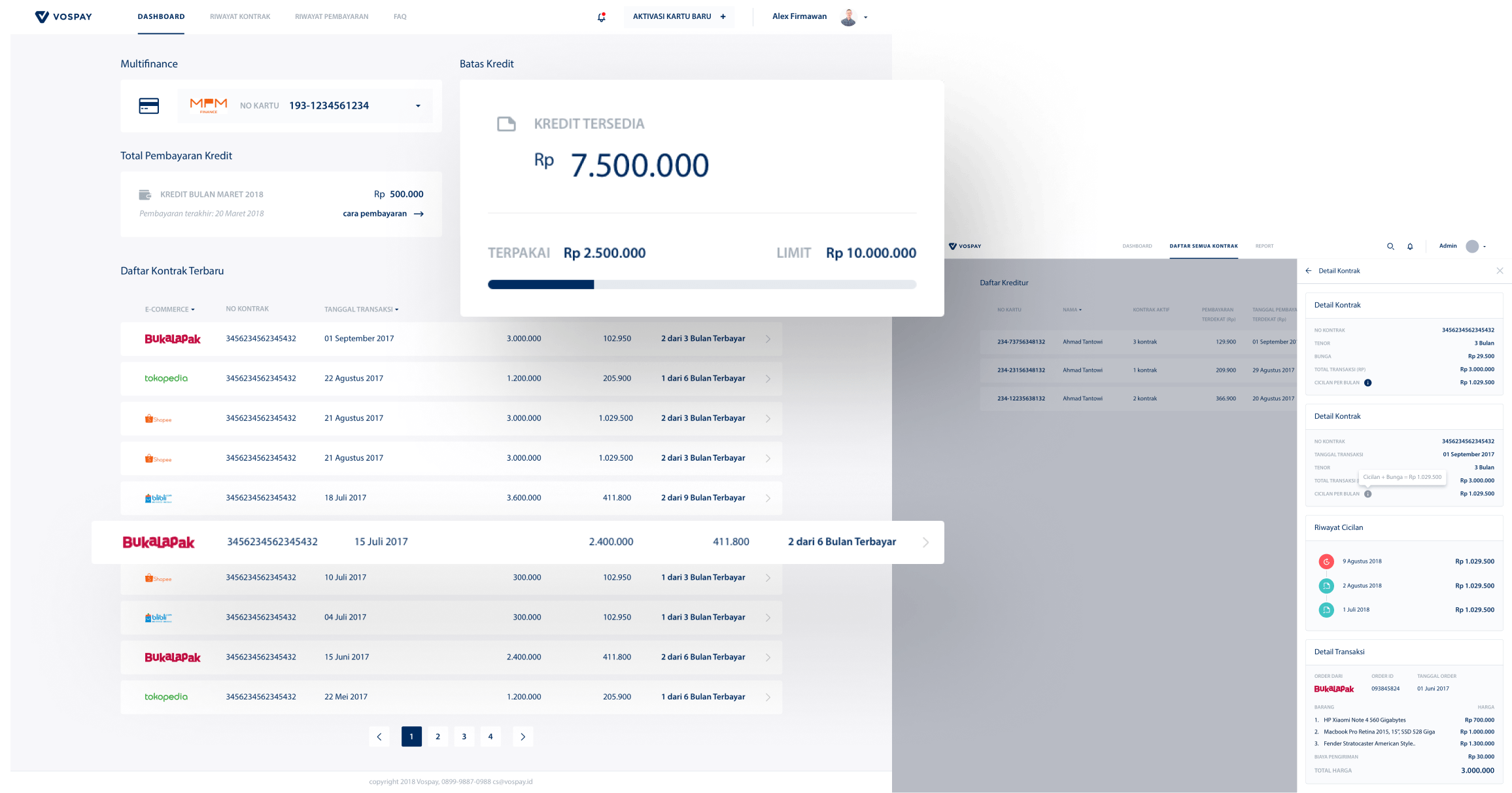
Vospay
Vospay is bridging multifinance customers with Indonesia's e-commerce platforms. I was responsible for building the dashboard, account registration & activation interface.
Build at Kodefox
Maintain
Marketwurks
Marketwurks is an app that allows you to easily and affordably manage your market. I help maintain the application by fixing bugs and build new features.
Build
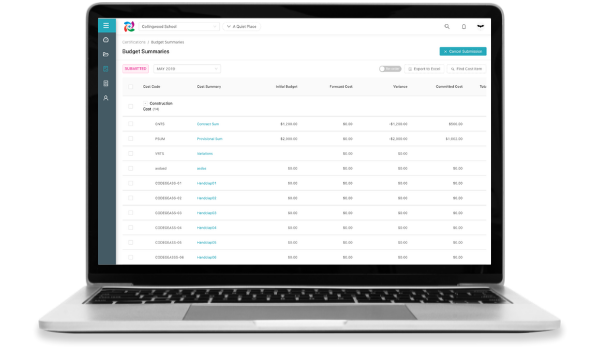
Procost
Procost is a budget management software for construction companies. I was responsible for building the frontend side of the application.
Build at GDIS
Occasionally, I did some workshops and events, although I wasn't doing much lately.
Me and 2 of my colleagues did a full week workshop on React for BTPN and Jenius team.
Me and my colleagues went to Tech in Asia to represent Zumi (a Kodefox made app) in Tech in Asia Conference!
Feel free to reach me through my email or slip in DMs on any of my social network.